A Short Guide to SVM
SVM stands for Support Vector Machine. It is a supervised machine learning algorithm and one of the popular classification methods that can also perform multi-class classification. Though SVM is not limited to classification, it can also be used for regression tasks. In this post, we will focus on classification to explain the underlying concept of Support Vector Machine.

The IDEA
The main idea behind SVM is to find the Optimal Hyperplane that divides or classifies the data into different classes, thereby maintaining a suitable margin. Let’s break this statement down and try to understand what’s going on.

Why SVM ???

Consider the two data points in the above image. The one on the left can be divided into 2 classes using just a simple line. Such data is called Linearly Separable Data, but the data point on the right image cannot be separated using a linear decision boundary (linear line).
Such data can be separated/classified at higher dimensions using HYPERPLANES.
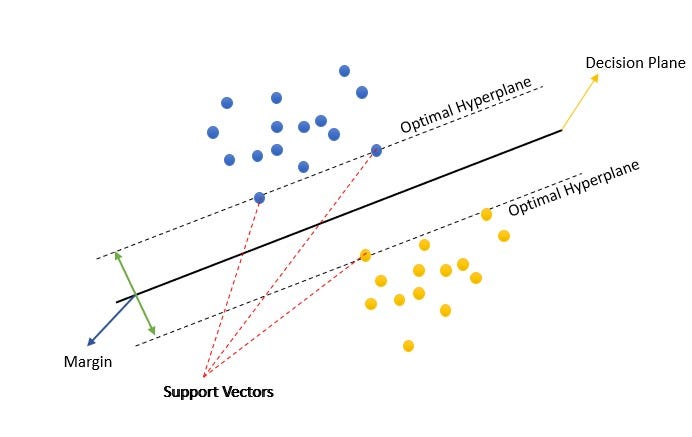
What is a Hyperplane ???
In 2D, a hyperplane is basically a line, dividing 2 or more classes. When we go to dimensions higher than 2D, a hyperplane is an actual plane dividing the data at different levels. These hyperplanes help to define the decision boundaries between different classes in Support Vector Machines.

How to chose an Optimal Hyperplane ???
SVM aims at maximizing the margin between classes. Margins can be of 2 types: Small margin and Large Margin.

Ideally, a model with a large margin is considered a better model, as the distance between the classes will be large, and data will be distinctly classified. For datapoints that might lie between the decision plane and hyperplane, a large margin will better serve as a deciding factor for which class it belongs to.
Underlying mantra: Higher Margin :: Better Model
Q: But how are margins defined ??
Ans: Using Support Vectors.
What are Support Vectors ???
Support Vectors are points that help to define the position, angle, and margin of a hyperplane. Support vectors are representative points of each class. Based on the position of these points, the position and distance between the hyperplanes will change. In the ideal case, the points that lie on the hyperplane are called Support Vectors or SV.
Parameter Tuning In SVM
Regularization (C)
The regularization parameter helps to control the misclassification rate in SVM. In python, the regularization parameter is defined using ©.
In terms of SVM, regularization works as follows:

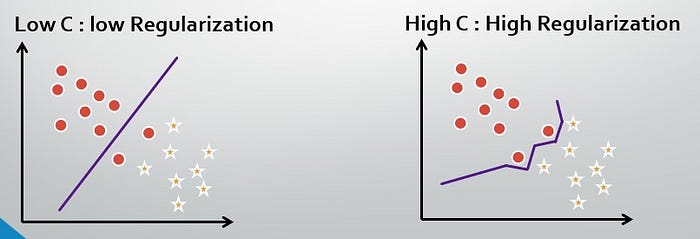
A Low C value results in forming large margin since regularization will not be strict and in such a case it might contain some misclassified points.
A High C value will result in smaller margin(strict regularization), hence misclassification rate will be low.
Gamma
Gamma is a measure to check how far the influence of dataset goes in defining the position of hyperplane. Basically it determines the number of support vectors to take into consideration while defining the position of the hyperplane.
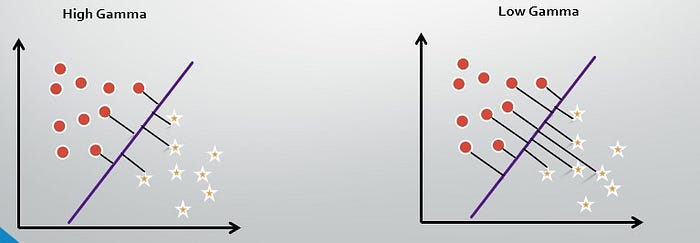
High Gamma: Only consider the points on or close to the hyperplane.
Low Gamma: Will also consider points at a distance from the hyperplane.
Kernels
Kernels are transformative parameters, i.e. based on the complexity of the dataset, kernels helps to transform the data into desired form.
Kernels allows to add dimensions to the dataset and raise the data to n-dimensions for classification. This is known as kernel trick method.
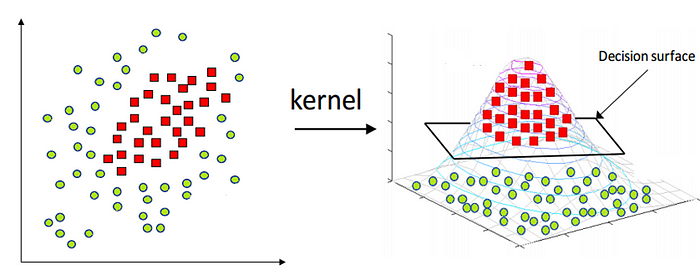
SVM uses different type of kernel functions. You can read more about the kernel functions and the math behind it here. The most commonly used kernel functions are:
- Linear
- Polynomial
- rbf (radial basis function)
Decision Boundaries for different kernels :
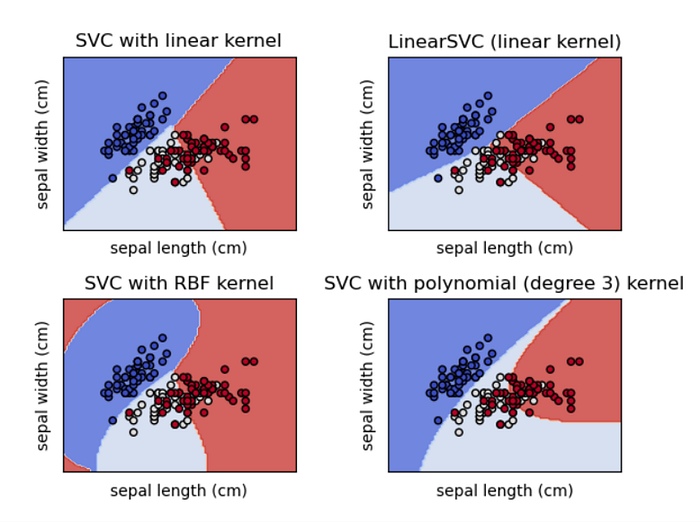
Hope this article gave you an intuitive understanding of how support vector machine works.
Chao…
